
Introduction
Machine learning (ML) is a collection of technologies that has matured in recent years and offers many potential opportunities to help Mishcon de Reya deliver value to clients. Broadly speaking, the technologies are a collection of different methods for finding and then using regularities or patterns in data.
Applications would include helping to increase productivity of legal professionals and provide them with a set of tools that can help them focus less on administrative and repetitive tasks, enabling them to spend more time with the clients and on the practise of law.
At Mishcon de Reya, we have been working to find the ways to harness the power of the data and ML to provide client value. Early successes include reducing the lawyers’ workload related to timekeeping by working with MDRLab, our startup accelerator programme, and company PING.
We have explored several options of leveraging Natural Language Processing (NLP). The term ‘Natural language processing’ (NLP) is normally used to describe a computer system which can analyse or synthesise spoken or written language. We now experience these types of system daily as consumers though conversational interfaces like Apple’s Siri or Amazon’s Alexa.
NLP made headlines in 2018 as breakthrough year in NLP research. Language modelling underwent a revolution as researchers managed to adopt large, simple, scalable techniques to text data that had previously only worked well in areas like computer vision – understanding images from cameras.
NLP technology is potentially of great importance to the industry of Law. Models for a variety of NLP tasks, such as question and answering or summarisation, are potentially important components for a wide range of legal machine learning systems. These tasks may include examining whole sets of legal documents but may also include a broad range of tasks that can support automation in the digital workplace.
Research at Mishcon
The use of Judicial Codes (J-Codes) for timekeeping has become mandatory in England and Wales in 2018. J-Codes are meant to give a structure to the legal litigation proceedings and help in tracking costs.
The Data Science team at Mishcon teamed up with the researchers from University College London and created an ML solution that learns and extracts context from the short legal narratives and suggests the appropriate J-Code.
The work included adapting a new version of an algorithm called BERT – model developed by Google AI – that has presented state-of-the-art results on the wide variety of NLP tasks, sometimes even surpassing human performance.
To achieve these recent performance improvements, researchers have developed a variety of techniques for training general purpose language representation models using the enormous amount of unannotated text from the web, using a technique known as pre-training.
The pre-trained model can then be adjusted for specific NLP tasks like question answering, resulting in substantial accuracy improvements compared to training on these task specific datasets from scratch. Interestingly, models with access to pre-trained language knowledge now provide state-of-the-art results on benchmark datasets like GLUE link tasks and also outperform human baselines in some cases.
The Data Science team had a oppotunity to present some of our research in this area during the recent Workshop on AI vs. Intelligent Assistance for Legal Professionals in the Digital Workplace (LegalAIIA) organized as part of ICAIL 2019 (International Conference on Artificial Intelligence and Law) in Montreal, Canada in June 2019.
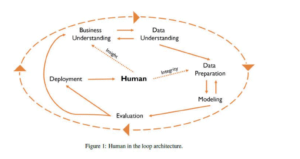
Human in the Loop
We are committed to the long term changes in the way the law is practiced and enhanced by technology.
We are utilising the best that technology has to offer in terms of NLP. Tools like Kira have been deployed in Real Estate for contract analysis, along with Relativity in Mishcon Discovery for predictive coding problems.
The vision of fully automated assistance provided by machines to legal professionals is not yet achievable. Towards this end, we have also been working on the frameworks to deploy the results of our research by creating a human in the loop structures.
Our approach aims to develop a cross industry standard process for data mining with the legal professional at the very center of it (see Figure 1).